1. Lossless Compression
According to Shannon`s source coding theorem [
16], the compression ratio of lossless data compression is closely related to the entropy value of data which can be derived from how likely each source symbol to appear. The theorem basically says for a vector consists of N elements where each element is from the source symbol set E, if the distribution of occurrence of source symbols in the vector is independent and identically distributed random and the entropy of the information the vector has is $H(X)$ bits, then the lower bound of the data size when the vector is lossless compressed is $N$ $H(X)$ bits as $N \to \infty$.
Example of the lower bound of the code word length.
Fig. 1 is an example to illustrate how this principle can be applied to obtain an ideal compression ratio for register accesses. The first row shows an access stream consists of seven 2-bit thread register accesses. Thus 14 bits are needed to store the entire trace without compression. The second row shows only 13 bits are needed to store when the trace is compressed, with a hypothetical algorithm which maps from the source symbol $E \in \{0$, $1$, $2$, $3\}$ to the code word $c(X) = \{$``0'': 110, ``1'': 0, ``2'': 10, ``3'': 111$\}$. The lower bound of a code word based compression can be obtained from the results of entropy theory. Assuming the entropy $H(X)$ is given as a prior knowledge, the upper bound of the compression ratio, $C(X)$, can be derived from $E$ and $H(X)$ as follows:

where $\left| E \right|$ represents the number of elements in the set $E$. The last row shows how to calculate the lower bound of the code word length is 12.897 bits from the given $H(X)$ as shown in Fig. 1, which corresponds to the compression ratio of 1.086.
2. Entropy Model
The key of our model is how to obtain $H(X)$ for register values. We first need assumptions about the compression granularity. The choice in this paper is to view each thread register value as a symbol. The insight under this decision is that there is structural value similarity between thread registers within a warp register [
5], thus our selection can capture such similarity as well as benefits with optimal entropy coding. Further, we assume each thread register is 32-bit wide which is quite a common choice as most GPUs are optimized for 32-bit operations. Regardless of our choices, we believe the presented methodology is general enough to work with any other parameters.
Assume that $E$ is the set of all possible register values, thus $E=\{0$, $1$, $2$, $\dots$, $2^{32}-1 \}$ for a 32-bit wide register. We also define the sample space $\Omega$, which is a trace of register values observed during program execution. $\Omega$ can be constructed by collecting the register values written back to the register file while running applications on a simulator.
A discrete random variable for a register value observation event $X$ can be defined as $X :$ $\Omega \to E$. Since the register values are discrete by nature, we can define the probability mass function (PMF) $f_X(x)$ of $X$ which is defined as
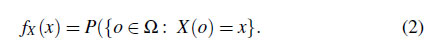
$f_X(x)$ can be obtained by counting the number of occurrences for each register value $e \in E$ in $\Omega$. To derive $H(X)$, the information content $I(x)$ which is defined as the following:

$I(x)$ means the amount of information in bits when a particular register value $x$ is observed. Finally, the entropy $H(X)$ can be calculated from $I(x)$ as follows.
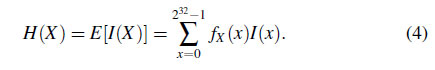
3. Optimizing for Application and Data Types
Eqs. (1) and (4) imply that the ideal compression efficiency is determined from $f_X(x)$, and as the distribution of $f_X(x)$ is closer to uniform distribution the maximum achievable compression ratio $C(X)$ will approach to 1.0 as the entropy $H(X)$ will increase. At extreme, if $f_X(x)$ is a discrete uniform distribution, all register values will occur equally likely. In this case, the entropy is calculated as the following:
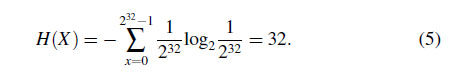
$I(x)$ means the amount of information in bits when a particular register value $x$ is observed. Finally, the entropy $H(X)$ can be calculated from $I(x)$ as follows.
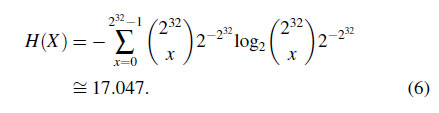
In this case, the ideal compression ratio is $32/17.047 = 1.87$. Because entropy $H(X)$ varies according to $f_X(x)$, then it is needed to use different $f_X(x)$ for each application to better model ideal performance, as $f_X(x)$ will vary according to application characteristics. Our model uses different $f_X(x)$ for each application by collecting register access trace separately for each benchmark.
In similar reasons, our model can be further improved by accounting for data types, which leverages the fact that $f_X(x)$ also varies according to registers' data types. Fig. 2 shows the portion of register values for each of the four different data types: Signed integer (S32), unsigned integer (U32), floating point (F32), and untyped bit (B32). Registers with different data types will have different value patterns, thus optimizing the compression algorithm for each data type will likely lead to a higher compression ratio. Also, this result shows the most frequent data type is different in each of the applications, which further supports the argument that the optimal algorithm has to consider $f_X(x)\ $variation across applications.
Ratio of register value data types (a) Fermi configuration, (b) Volta configuration.
Our model uses four conditional entropy values for the four data types, $H(X\mid S)$, $H(X\mid U)$, $H(X\mid F)$, and $H(X\mid B)$, where $T \in \{ S$, $U$, $F$, $B \}$. Each element in T means S32, U32, F32, and B32, respectively. The aggregated entropy $H(X)$ can be derived from the conditional entropy values and the portion of register accesses to each data type. The derivation is as follows:
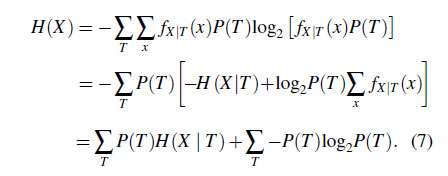
4. Latency Model
The program characteristic can be classified to compute-bounded or memory-bounded by analyzing the average stalled cycle of SM [
2]. Under the phase of compute-bounded workloads, the core's average stalled cycle decreases, since execution units of SM are fully utilized. In this section, capability of SM directly influences the overall performance. On the contrary, SM's average stalled cycle increases when GPU encounters memory-bounded phase of the application. Because of the latency of the memory access or preparing the data for computation, the pipeline should wait until the access or preparation is finished.
Fig. 3 shows the ratio of the average stalled cycle during the heartwall application which is in Rodinia benchmark suite [
17]. As shown in the figure, the characteristic of the ratio of the average stalled can be divided into two types, highly stalled phase and nearly non-stalled phase. These two phases appear one after the other during the execution of the application. To classify the application's characteristics whether the compute-bounded or memory-bounded, we use measured values of the stalled cycle's ratio. When the average ratio of compute-intensity is larger than memory-intensity, we can classify this phase as compute-bounded phase.
Register compression introduces additional latency while fetching values from registers in compute-bounded phase. On the other hand, memory work is the bottleneck of the memory-bounded phase. Therefore, the memory-bounded phase is not influenced by register compression. Equation 8 shows the relative performance of the GPU that Amdahl's law [18] is applied to compute-bounded phase and memory-bounded phase.
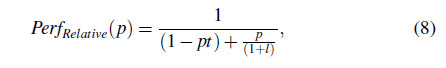
where $p$ is the portion of compute-bounded phase ($0 \le p\le 1$) and $l$ is the additional latency of register compression.